데이터분석준전문가(ADsP)/3과목
[정형데이터 마이닝 ] 데이터 마이닝
- -

목차
1. 데이터 마이닝의 정의
1. 대량의 데이터 집합으로부터 유용한 정보(Knowleage)를 추출하는 것
2. 의미있는 패턴과 규칙을 발견하기 위해서 자동화되거나 반자동화된 도구를 이용하여 대량의 데이터를 탐색하고 분석하는 과정
3. 통계 및 수학적 기술 뿐만 아니라 패턴 인식 기술들을 이용하여 데이터 저장소에 저장된 * 대용량의 데이터를 조사함으로써 의미있는 새로운 상관관계, 패턴, 추세 등을 발견하는 과정
*대용량데이터: 이 때 대용량 데이터를 저정한 장소는 데이터 웨어하우스이다. 데이터 베이스는 현재 운영하고 있는 시스템임 착각 노노
적용된 예시 사례
1. 구매 패턴의 발견
추천지수 A라는 책을 산 사람이 B라는 책을 샀고 이런 데이터를 모아서 사례분석기반이라는 방법, 연관성 분석 (Association rule discovery)을 사용해서
2. 자동 문서 분류 - 메일 스팸 필터링
3. GS 홈쇼핑 DM 발송 등
데이터 마이닝이란
Knowledge Discovery in large Databases(KDD)
대량의 데이터로부터 이전에 알려지지 않은,
묵시적이고잠재적으로 유용한 정보를 탐사하는 작업
Business Interlligence(BI와의 차이점)
BI: 경영진들이 합리적인 의사결정을 내리기 위하여 데이터를 수집, 저장, 처리하는 분석하는 일련의 기술 및 응용시스템으로 포괄적 개념 이것을 하기 위한 도구가 데이터마이닝이라고 할 수 있다.
데이터 마이닝 : BI의 일부로 데이터 분석과정
01-2 통계분석과의 차이점
통계분석은 가설이나 가정에 따른 분석 방법이지만 데이터마이닝을 다양한 수리 알고리즘을 통해 데이터베이스의 데이터로부터 의미있는 정보를 찾아내는 방법을 통칭한다.
01-3 종류
| 정보를 찾는 방법론에 따른 분류 | 분석대상, 활용목적, 표현방법에 따른 분류 |
| 인공지능(Artificial Intelligence) | 시각화분석(Visualization Analysis) |
| 의사결정나무(Desicion Tree) | 분류(Classification) |
| K-평균군집화(K-means Clustering) | 군집화(Clustering) |
| 연관분석(Accociation Rule) | 포케스팅(Forecasting) |
| 회귀분석(Regression) | |
| 로짓분석(Logit Analysis) | |
| 최근접이웃(Nearest Neighborhood) |
01-4 사용분야
병원에서 환자 데이터를 이용해서 해당 환자에게 발생 가능성이 높은 병을 예측
기존 환자가 응급실에 왔을 때 어떤 조치를 먼저 해야 하는지를 결정
고객 데이터를 이용해 해당 고객의 우량/불량을 예측해 대출적격 여부 판단 세관 검사에서 입국자의 이력과 데이터를 이용해 관세물품 반입 여부를 예측
01-5 데이터마이닝의 최근 환경
데이터마이닝 도구가 다양하고 체계화되어 환경에 적합한 제품을 선택하여 활용 가능하다. 알고리즘에 대한 깊은 이해가 없어도 분석에 큰 어려움이 없다. 분석 결과의 품질은 분석가의 경험과 역량에 따라 차이가 나기 때문에 분석 과제의 복잡성이나 중요도가 높으면 풍부한 경험을 가진 전문가에게 의뢰할 필요가 있다. 국내에서 데이터마이닝이 적용된 시기는 1990년대 중반이다. 2000년대에 비즈니스 관점에서 데이터 마이닝이 CRM의 중요한 요소로 부각되었다. 대중화를 위해 많은 시도가 있었으나, 통계학 전문가와 대기업 위주로 진행되었다.
데이터 마이닝과 CRM
- CRM을 수행한 위한 필수 요소 기술
- 운영 시스템으로부터 수집된 데이터를 분석하여 CRM을 수행하는 실제적인 활동을 만드어 내는 것을 의미
- 우량 고객 유지 : 우량 고개 지역/ 상품특성 등 분석
- 이탈 고객 분석 : 과거 이탈 고객의 정보를 학습하여 유사 특성을 보이는 고객을 특별 관리
- 잠재 고객 발굴 : 기존 고객의 모습과 비슷한 모습을 갖고 있는 고객 그룹을 인식
2. 데이터 마이닝의 분석 방법
| 지도학습 분석 기법 (Supervised learinig) | 자율학습 분석 기법(Unsuperviese learning) |
| 의사결정나무 (Dicision Tree) | 연관성 규칙 (Association Rule Discovery) |
| 인공신경망(ANN, Artificial Neural Network) | 군집 분석 (K-means Clustering) |
| 일반화 선형 모형 (GLM, Generalized Linear Model) | OLAP(on-line analytical Processing) |
| 회귀분석( Regression Analysis) | SOM(Self Organizing Map) |
| 로지스틱 회귀분석( logistic regression analysis) | |
| 사례기반 추론(Case- based Reasoning) | |
| 최근접 이웃법(KNN K-nearest Neighbor) |
교사학습(지도학습)과 비교사학습(비지도학습)에 활용되는 데이터마이닝 분석 방법 중요 (시험 자주 출제)
3. 분석 목적에 따른 작업 유형과 기법
| 목적 | 작업유형 | 설명 | 사용기법 |
| 예측(Preditive Modeling) | 분류규칙(Clssification) | 가장 많이 사용되는 작업으로 과거의 데이터로부터 고객특성을 찾아내어 분류모형을 만들어 이를 토대로 새로운 레코드의 결과값을 예측하는 것으로 목표 마케팅 및 고객 신용펴가 모형에 활용됨 | 회귀분석, * 판별분석, 신경망, 의사결정나무 |
| 설명(Descriptive Modeling) | 연관규칙(Association) | 데이터 안에 존쟇는 항목간의 종속관계를 찾아내는 작업으로, 제품이나 서비스의 교차판매(Cross selling), 매장 진열(DIsplay), 첨부우편(Attached Mailings), 사기적발(Fraud Detection)등의 다양한 분야에 활용됨 | * 동시발생 매트릭스 |
| 연속규칙(Sequence) | 연관규칙에 시간관련 정보가 포함된 형태로, 고객의 구매이력(history)속성이 반드시 필요하며, 목표 마케팅(target marketing)이나 일대일 마케팅(one to one marketing)에 활용됨 | * 동시발생 매트릭스 | |
| 데이터 군집화(Clustering) | 고객 레코드들을 유사한 특성을 지닌 몇 개의 소그룹으로 분할하는 작업으로 작업의 특성이 분류규칙(classification)과 유사하나 분석대상 데이터의 결과값이 없으며, 판촉활동이나 이벤트 대상을 선정하는데에 활용됨 | K-means Clustering(군집분석) |
* 판별분석 : 두 개 이상의 모 집단에서 추출된 표본들이 지니고 있는 정보를 이용하여 이 표본들이 어느 모집단에서 추출된 것인지를 결정해 줄 수 있는 기준을 찾는 분석법을 말합니다.
* 동시발생 매트릭스: 동시발생 매트릭스는 거래(사건) 속에 포함된 품목(항목)간의 연관관계를 발견하고자 할 때 사용하는 data mining 기법이다. 분석의 대상이 되는 데이터는 두 개의 변수, 즉 거래와 품목으로 구성되며, 각각의 거래에 대해 한 개 이상의 품목들이 존재한다. 일반적으로 하나의 거래는 한 고객에 의한 구매를 의미하며, 품목은 그 구매를 통해 구입된 물건이다. 동시발생 매트릭스는 확률을 이용하여 연관규칙을 제공하는데 먼저 하나의 품목에 대해, 다음으로 두 품목간의 연관규칙을 생성하며 계속해서, 세 품목간, 네 품목간 등으로 이어진다. 연관규칙은 "(품목 A)⇒(품목 B)"의 형태로 표현되며, "품목 A를 포함한 거래는 품목 B도 포함한다."라 해석한다.
4. 데이터마이닝 추진단계
4-1. 1단계: 목적 설정
데이터마이닝을 통해 무엇을 왜 하는지 명확한 목적(이해관계자가 모두 동의하고 이해할 수 있는) 을 설정한다.
전문가가 참여해 목적에 다라 사용할 모델과 필요한 데이터를 정의한다.
4-2. 2단계: 데이터 준비
고객정보, 거래정보, 상품 마스터 정보, 웹로그 데이터, 소셜 네트워크 데이터 등 다양한 데이터를 활용한다.
4-3. 3단계: 가공(데이터 정제)
모델링 목적에 따라 목적 변수를 정의한다.
필요한 데이터를 데이터마이닝 소프트웨어에 적용할 수 있는 형식으로 가공한다.
4-4. 4단계: 기법 적용( 데이터 마이닝 툴 설정)
1단계에서 명확한 목적에 맞게 데이터마이닝 기법을 적용하여 정보를 추출한다.
4-5. 5단계: 검증
데이터 마이닝으로 추출된 정보를 검증한다.
테스트 데이터와 과거 데이터를 활용하여 최적의 모델을 선정한다.
검증이 완료되면 IT부서와 협의하여 상시 데이터 마이닝 결과를 업무에 적용하고 보고서를 작성
하여 추가 수익과 투자대비성과(ROI)등으로 기대효과를 전파한다.
5. 데이터마이닝을 위한 데이터 분할
5-1 개요
모델 평가용 테스터 데이터와 구축용 데이터로 분할하여, 구축용 데이터로 모형을 생성하고 테스트 데이터로 모형이 얼마나 적합한지를 판단한다.
5-2 데이터 분할
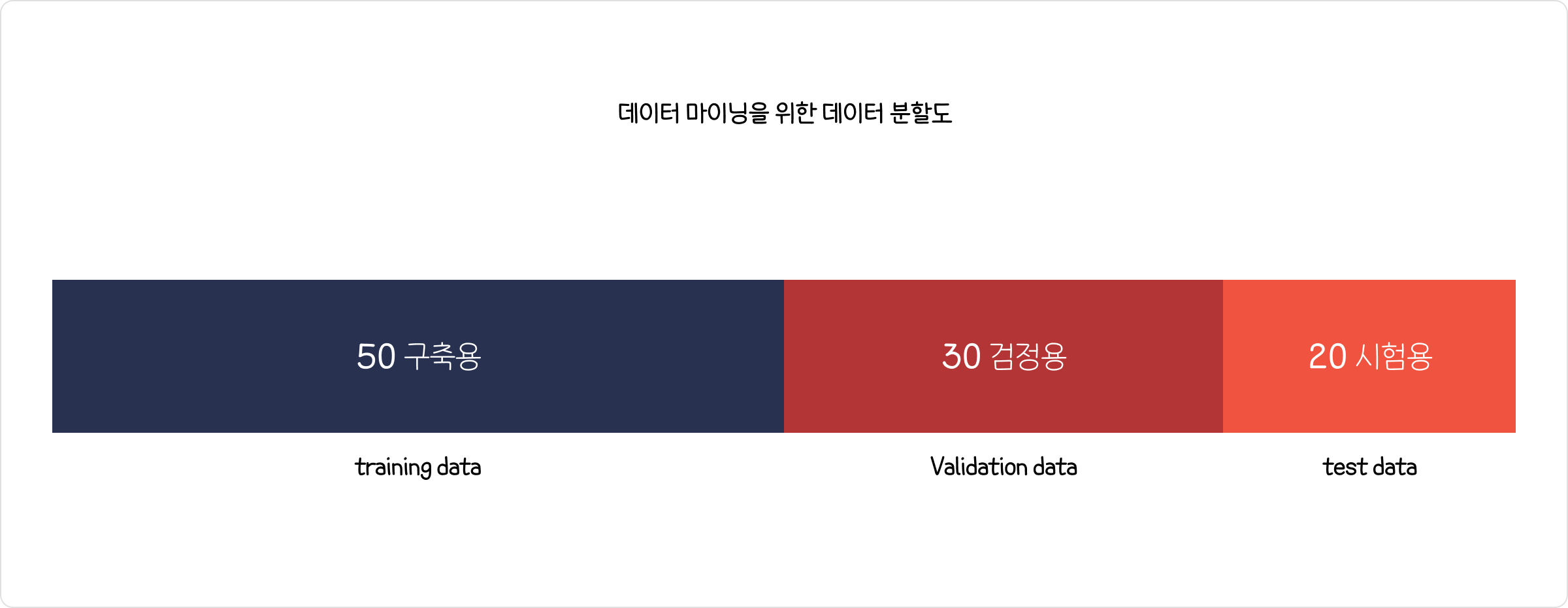
1) 구축용(training data 50%)모형 생성
추정용, 훈련용 데이터라고 불리며 데이터 마이닝 모델을 만드는데 활용한다.
2) 검정용(validation data, 30%)
구축된 모형의 과대추정 또는 과소추정을 미세 조정을 하는데 활용한다.
3) 시험용(test data, 20%)모형 적합도 판단
테스트 데이터나 과거 데이터를 활용하여 모델의 성능을 검증하는데 활용한다.
4) 데이터의 양이 충분하지 않거나 입력 변수에 대한 설명이 충분한 경우
홀드아웃(hold-out)방법 : 주어진 데이터를 랜덤하게 두 개의 데이터로 구분하여 사용하는 방법으로 주로 학습용(training data)과 시험용(test data)로 분리하여 사용한다.
교차확인(cross-validation)방법: 주어진 데이터를 k개의 하부집단으로 구분하여 K-1개의 집단을 학습용으로 나머지는 하부집단으로 검증용으로 설정하여 학습한다. k번 반복 측정한 결과를 평균낸 값을 최종값으로 사용한다. 주로 10-fold 교차분석을 많이 사용한다.
6. 성과분석
06-1 오분류 추정치

정분류율(Accuracy)
Accuracy = TN+FP /TN+TP+FN+FP
오분류율(error Rate)
1-Accuracy = FN+FP/TN+TP+FP+FN
특이도(Specificity) False를 False로 판정하는 정도
Specificity = TN/(FP+TN)
민감도(Sensitivity) true를 true로 판정하는 정도
Sensitivity = TP/(TP+FN) TNR(True Negative Rate)
정확도(Precision)
Precision = TP/ (TP+EN) TPR(Ture Positive Rate)
재현율(Recall): 민감도와 같음
Recall = TP/(TP+FN)
F1 Score 정확도와 재현율의 조화 평균
F1 = 2x(정확도x재현율)/(정확도+재현율)
정분류율, 특이도, 민감도, 재현율, F1 score을 구하는 문제가 자주 출제되고 있어서 수식을 정확히 숙지해야 한다.
정확도 비 AR
AR= 2* AUROC-100%
AUROC= (AR+1)/2
AR = TP+TN / n = 905/1000 = 90.5%
06-2 ROCR 패키지로 성과분석
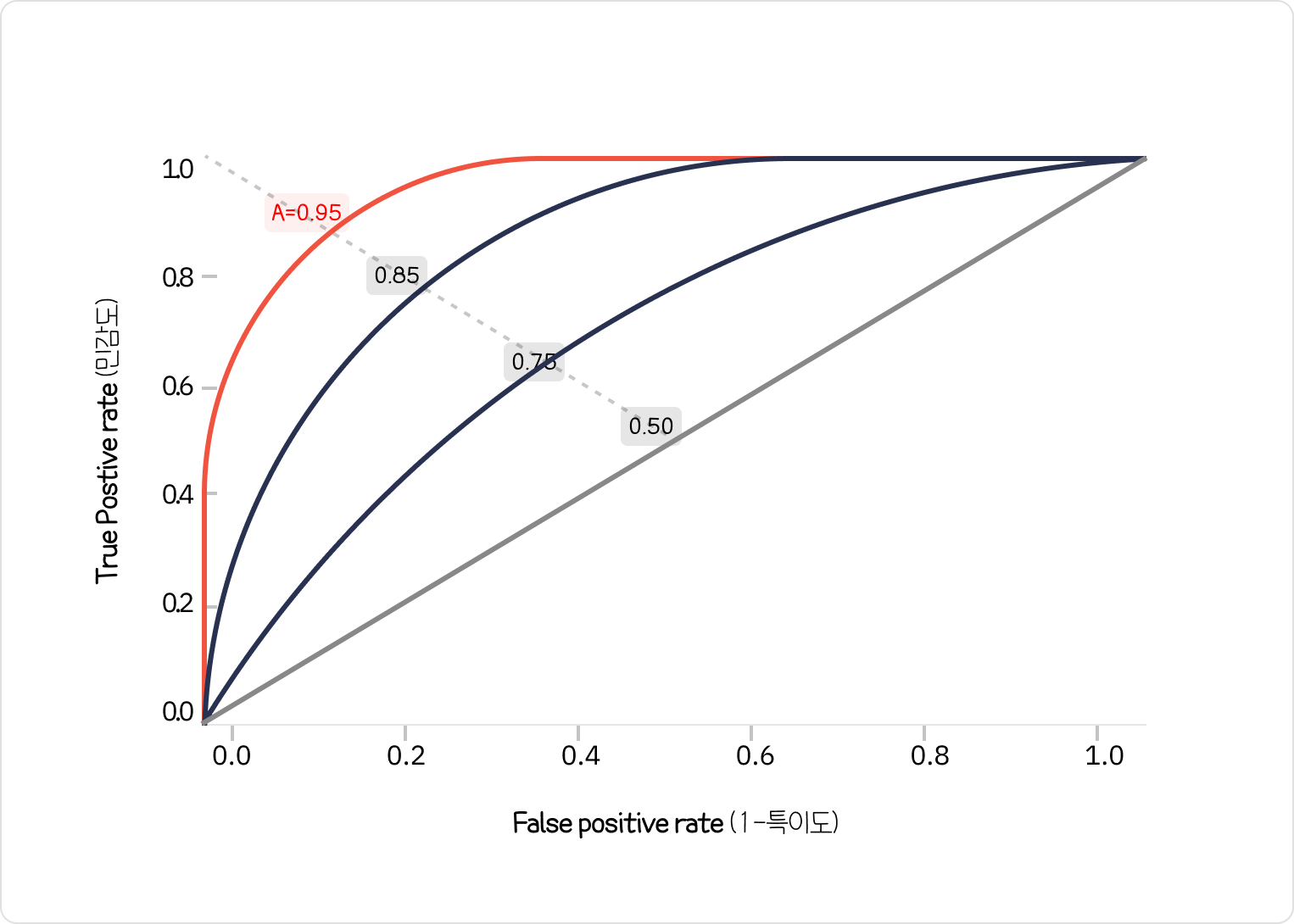
1) Roc Curve( Reciver Operating Caracteristic curve) 수신기 작동 특성
Roc curve란 가로축을 FPR(Flase Positive Rate=1-특이도) 값으로 두고, 세로축을 TPR(True Positive Rate=민감도) 값으로 두어
시각화한 그래프이다.
2진 분류(Binary classification)에서 모형의 성능을 평가하기 위해 많이 사용되고 있는 척도이다.
그래프가 왼쪽 상단에 가깝게 그려질수록 올바르게 예측한 비율을 높고, 잘못 예측한 비율은 낮음을 의미한다.
따라서 ROC 곡선 아래에 면적을 의미하는 AUROC(Area Under Reciver Operating Caracteristic)값이 크면 클수록
(1에 가까울수록) 모형의 성능이 좋다고 판단한다.
TPR(True Positive Rate , 민감도) 1인 케이스에 대한 1로 예측한 비율
FPR(False Positive Rate, 1-특이도) 0케이스에 대한 1로 잘못 예측한 비율
AUROC(Area Under Receiver Operating Curve) 를 이용한 정확도의 판단 기준
| 기준 | 구분 |
| 0.9~1.0 | Ecellent (A) |
| 0.8~0.9 | good |
| 0.7~0.8 | fair |
| 0.6~0.7 | Poor |
| 0.5~0.6 | fail |
2) ROC Curve와 Auroc 활용예시
3) R실습코드
ROCR 패키지는 Binary classification 만 지원가능
06-3 이익도표(Lift chart)
이익도표는 분류모형의 성능을 평가하기 위한 척도로, 분류된 관측치에 대해 얼마나 예측이 잘 이루어졌는지를 나타내기 위해 임의로 나눈 각 등급별로 반응검출율, 반응률, 리프트 등의 정보를 산출하여 나타내는 도표이다.
[이익도표 예시]
2000명의 전체 고객 중 381명(특정범주 빈도)이 상품을 구매한 경우에 대해 이익도표를 만드는 과정을 예로 들어보면 , 먼저 데이터셋의 각 관측치에 대한 예측화율을 내림차순으로 정렬한다. 이후 데이터를 10개의 구간으로 나눈 다음 각 구간의 반응율(% response)을 산출한다. 또한 기본 향상도(baseline lift)에 비해 반응률이 몇 배나 높은지를 계산하는데 이것을 향상도(Lift)라고 한다.
| Decile | Frequancy of "Buy" 구매빈도 |
%Captured Reponse(반응 검출률) | %Response(반응률) | Lift(향상도) |
| 1 | 174 | 174/381 =45.6 | 174/200=87 | 87/19=4.57 |
| 2 | 110 | 110/381= 28.8 | 110/200=55 | 55/19=2.89 |
| 3 | 38 | 38/381= 9.9 | 38/200=19 |
19/19=1.00 |
| 4 | 14 |
14/381=3.6 |
14/200=7 | 7/19=0.36 |
| 5 |
11 | 11/381=2.8 | 11/200=5.5 | 5.5/19=0.28 |
6 |
10 | 10/381=2.6 | 10/200=5 | 5/19=0.26 |
| 7 | 7 | 7/381=1.8 | 7/200=3.5 | 3.5/19=0.18 |
| 8 | 10 | 10/381=2.6 | 10/200=5 | 5/19=0.26 |
| 9 | 3 | 3/381=0.7 | 3/200=1.5 | 1.5/19=0.07 |
| 10 |
4 | 4/381=1.0 | 4/200=2 | 2/19=0.10 |
base lift =381/ 2000 = 19.05%
| Rank | Predicted Probability | Actual class |
| 1 | 0.95 | Yes |
| 2 | 0.93 | Yes |
| 3 | 0.93 | No |
| 4 | 0.88 | Yes |
base lift값을 구할 수 있다. 381/ 2000= 0.1905 19.5%
* 전체 2000명중에 381명이 구매
%captured Response:
반응검출율(%captured Response) = 해당 등급의 실제 구매자/ 전체 구매자
해당 집단에서 목표변수의 특정범주 빈도 / 전체 목표변수의 특정범주 빈도 X100
% Response: 반응률 = 해당 등급의 실제 구매자 / 200명
데이터를 10개의 구간으로 나누면 200이 된다.
Lift : 향상도 = 반응률(response)/ 기본 향상도 (Base lift)
좋은 모델이라면 Lift가 빠른 속도로 감소해야 한다.
과적합-과대적합, 과소적합의 개념
과적합-과대적합(Overfitting): 모형이 학습용 데이터(training data)를 과하게 학습하여, 학습 데이터에 대해서는 높은 정확도를 나타내지만 테스트 데이터 혹은 다른 데이터에 적용할 때는 성능이 떨어지는 현상을 의미한다.
과소적합(Underfitting): 모형이 너무 단순하여 데이터 속에 내제되어 있는 패턴이나 규칙을 제대로 학습하지 못하는 경우를 의미한다.
반응형
'데이터분석준전문가(ADsP) > 3과목' 카테고리의 다른 글
| [정형데이터 마이닝] 분류분석 (0) | 2021.08.27 |
|---|---|
| [정형데이터 마이닝] 연관분석 (0) | 2021.08.26 |
| [정형데이터 마이닝] 군집분석 (0) | 2021.08.25 |
| [통계분석] 주성분분석 (0) | 2021.08.14 |
| [통계분석] 다차원척도법 (0) | 2021.08.14 |
| [정형데이터마이닝] 앙상블 분석 (0) | 2021.08.14 |
| [통계분석] 시계열 분석 (3) | 2021.08.13 |
| [통계분석] 통계기초 - 수학기호&통계기호 (1) | 2021.08.12 |
Contents
소중한 공감 감사합니다