데이터분석준전문가(ADsP)/3과목
[통계분석] 통계기초 - 수학기호&통계기호
- -

통계 기호 l
| 상징 | 기호 이름 | 의미/정의/예시 |
| P ( x ) | 확률 밀도 함수 (pdf-probability density function ) |
P ( a ≤ x ≤ b ) = ∫ f ( x ) dx |
| P ( A ) | 확률 함수 | 사건 A의 확률 |
| P ( A ∩ B ) | 사건 교차 확률 | 사건 A와 B의 확률 |
| P ( A ∪ B ) | 사건 합동 확률 | 사건 A 또는 B의 확률 |
| P ( A | B ) | 조건부 확률 함수 | 이벤트 B가 발생한 경우 이벤트 A의 확률 |
| Σ | 통계에서는 수열의 합. | 시그마. 수열의 모든 항을 더한것 더하다는 뜻 sum 에서 유래하여 그리스 기호 시그마로 s로 나타낸다. |
| F ( x ) | 누적 분포 함수 (cdf-Cumulative distribution function) |
F ( x ) = P ( X ≤ x ) |
| E ( X ) | 기대값 | 통계에서 기대값은 평균과 같다고 생각하면 된다. 가능한 값마다 확률을 곱해서 모두 더한 것이다. 확률변수 X의 평균으로 보통E(x)라고 쓴다. |
| exp(x) | 기대값 | exp는 expectation, expected value이다. |
| ∫ | 적분 (인테그럴) |
적분. 적분이란 정의된 함수의 그래프와 그 구간으로 둘러싸인 도형의 넓이를 구하는 것이다.s자 알파벳으로 오인할 수도 있는데 적분 기호는 길쭉한 기호 이다. |
| E ( X | Y ) | 조건부 기대 | Y가 주어진 임의 변수 X의 기대 값 예시 ) P ( X | Y = 2 ) = 5 |
| var ( X ) | 변화,변수,분산 (Variance) | 랜덤 변수 X의 분산 |
| σ | 모수 | 표본 관측에 의해 구하고자 하는 모집단에 대한 정보 |
| μ | 모평균(뮤) | 모집단의 평균 |
| σ² | 모분산 | 관측값에서 모 평균을 빼고 그것을 제곱한 값을 모두 더한것을 n-1로 나눈것이다. 관찰값들이 얼마나 퍼져 있는지를 구하는 방법이다. 분산을 알기 위해서는 먼저 평균을 알아내고, 각각 관찰값들과 평균 사이의 거리(distance)를 구하기 위해 관찰값에서 평균을 빼게 된다. 이때 평균이 음의 수인것은 평균을 내기 어려워서 과거에는 양의 수로 모두 바꿔서 계산을 하려고 제곱을 하게 됐다. |
| σ | 모표준편차 | 모분산σ²에 루트를 씌운것이다. 위의 모분산 설명을 보면 모표준편차에서 왜 루트를 씌우는지 알 수 있는데 평균을 계산하기 위해 제곱했던것에 다시 루트를 씌워서 원래 값으로 돌리기 위함이다. |
| Ω | 모집단, 표본공간(sample space)(오메가) |
모집단이나 표본공간 모든 사건의 수를 오메가로 표현한다.확률에서는 표본공간(sample space)를 말한다.표본공간이란 실험의 결과 하나하나를 모두 모은것 |
| 표준 (X ) | 표준편차 | 랜덤 변수 X의 표준 편차 |
| s | 표본표준편차 (Standard deviation) |
|
| s² | 표본분산 | 모평균(모집단의 평균)을 추정하기 위한 추정량, 확률표본의 표본값 |
x̄ |
표본평균(sample mean) | 확률표본의 평균값. 표본통계량이란 표본평균이나 표본분산처럼 표본의 특성을 나타내는 대푯값 을 말한다. X 언더바로 읽는다. |
| N ( μ , σ ) | 정규분포 ,가우스분포 | |
| n ! | 계승 (팩토리얼) | n ! = 1⋅2⋅3⋅ ⋅ ... N 계승은 자연수만을 정의역으로 둔다. 모든 자연수 항을 곱한다. 팩토리얼이라고 읽는다. 0!은 특별히 1로 생각하면 된다. |
| n P k | 순열 | |
| 기하 ( p ) | 기하학적 분포 | f ( k ) = p (1 -p ) k |
| X ~ | X 분포 | 랜덤 변수 X의 분포 |
| iid | 독립분포 | |
| χ² | 카이제곱분포 | |
| p-value | p값 | 유의확률, 유의수준, 제1종 오류가 발생할 확률이다. 가설검정에서 쓴다. |
| lim n→∞ |
총 시행횟수(무한대로 표현) | 변수가 일정한 법칙에 따라 정해진 값에 한없이 가까워질 때의 값 함수(또는 수열)의 값이 어떠한 값으로 가까워지거나, 또는 점점 멀어지는 움직임을 나타낸다. 연속성을 가진 연속형 확률변수를 정의할때 씀 |
| λ | 푸아송분포 (람다) |
포아송 분포(혹은 푸아송) 에서 정해진 시간 안에 어떤 사건이 일어날 횟수에 대한 기댓값 람다: 정해진 시간 안에 어떤 사건이 일어날 횟수에 대한 기댓값 |
| Γ | 감마 | 모든 항을 곱할때 쓰는 기호 팩토리얼처럼 0이하로는 정의하지 않음, 계승함수(팩토리얼)의 성격을 가지고 있다. [예시] Γ(n)=(n−1)! (nn이 자연수일 경우) Γ(n+1)=Γ(n)Γ(n+1)=nΓ(n) Γ(1)=1Γ(1)=1 |
| ∆ | 델타 | 최소값부터~최대값까지 |
| ^ | 곱셈 | 캐럿이라고 읽는다. |
| ∏ | 곱연산 | 계속 곱해 나가라는 뜻 |
| r | 피어슨 상관계수 | 표본 상관계수 계산방식. 적률상관계수, 연속형변수, 정규성 가정에 대부분 많이 사용 |
| 𝜌 | 스피어만 상관계수 | 로우라고 읽음. 순위상관계수, 순서형 변수, 비모수적 방법, 순위를 기준으로 상관관계 측정, 서열척도 (P 모양과 비슷해 보일 수 있음 주의) |
| COV | 공분산(covariance) | 두 확률변수 X,Y를 한꺼번에 놓는 방향의 조합이다. |
| Corr | 상관계수 | |
| ~ | ~따라서 ~ | [예시] b+1 ~ X(n+1) b+1은 따라서 x(n+1)로 규정된다. |
| ≈ | 근사값이다. | [예시 ]y ≈ X (y는 x의 근사값) |
| ∝ | 비례기호(proportionality sign) | [예시] A∝B A는 B에 비례한다. |
| θ | 미지의 기울기 수 (세타) | 최대우도 추정법등에서 사용 |
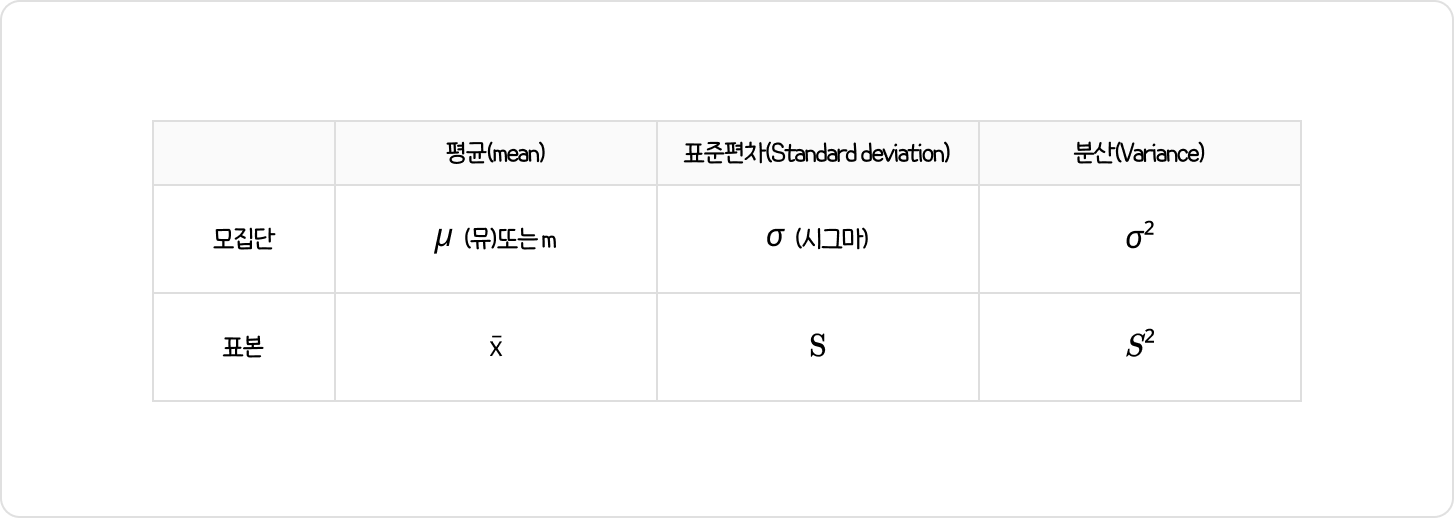
모집단VS 표본
분산들의 특징: 제곱 기호가 붙는다. 모분산, 표본분산
수식에서 모분산이 뭔지 할때는 분자에 σ를 넣고, 모분산을 모를 때는 분자에 S를 넣음
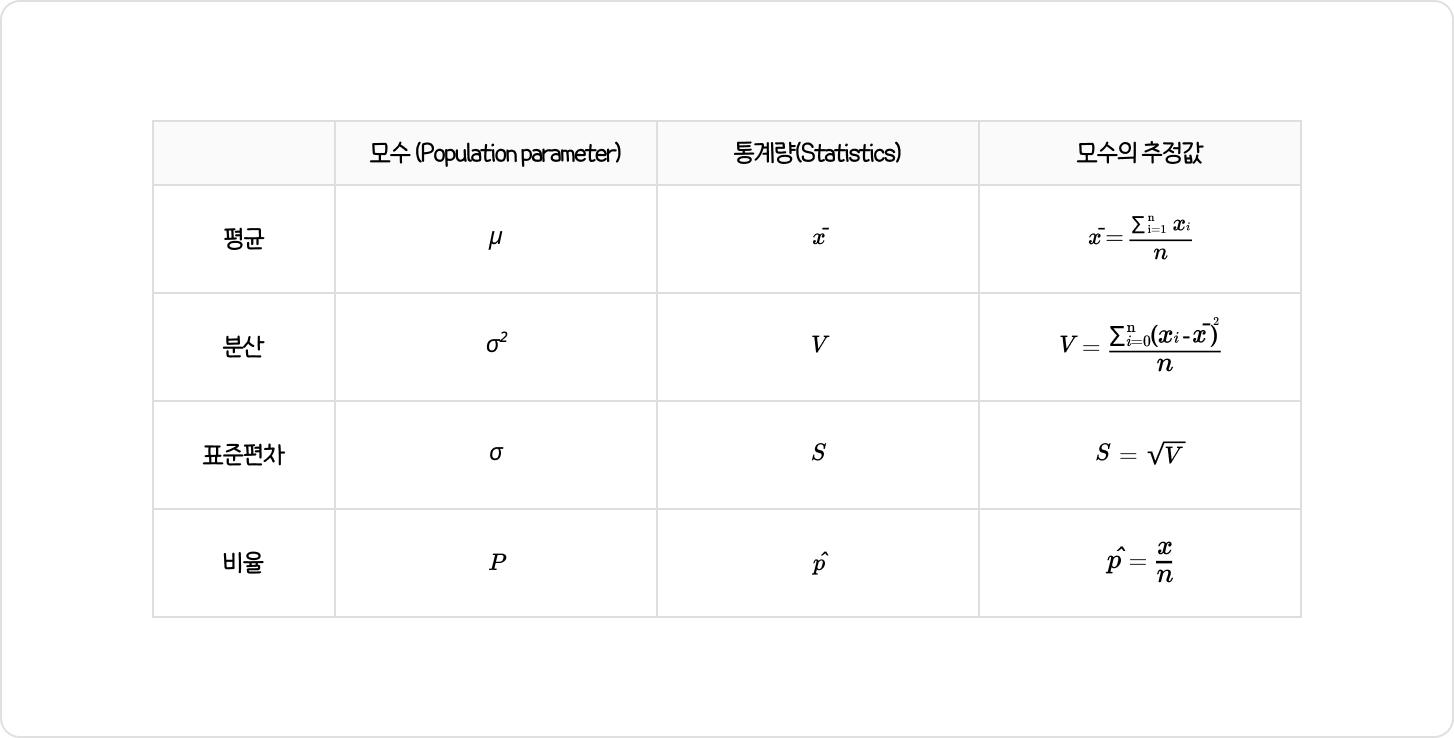
평균, 분산, 표준편차, 비율
1. 수포자인 제가 더듬더듬 데이터분석준전문가를 공부하면서 모아 본 자료입니다. 기호 읽는 법도 몰라서 읽는 법까지 작성되어 있습니다.
2. 똑똑하신분들 보완할 점을 알려주시거나 오타가 있는걸 발견했다하면 댓글로 알려주세요! 복받으실거에요
3. 혹시나 도움 되셨다면 커피값도 안되지만...음료 한잔 쏘고 간다고 생각하시고 하단 광고 클릭 한번 해주고 가시면 참 감사하겠습니다!
4. 마지막으로 공부하시는 분들 모두 좋은 성적 거두시고, 잘 되시길 바래요 😍
반응형
'데이터분석준전문가(ADsP) > 3과목' 카테고리의 다른 글
| [정형데이터 마이닝] 군집분석 (0) | 2021.08.25 |
|---|---|
| [정형데이터 마이닝 ] 데이터 마이닝 (0) | 2021.08.21 |
| [통계분석] 주성분분석 (0) | 2021.08.14 |
| [통계분석] 다차원척도법 (0) | 2021.08.14 |
| [정형데이터마이닝] 앙상블 분석 (0) | 2021.08.14 |
| [통계분석] 시계열 분석 (3) | 2021.08.13 |
| [통계분석] 회귀분석 - 기초 (0) | 2021.08.11 |
| [통계분석] 통계분석의 이해 (0) | 2021.08.08 |
Contents
소중한 공감 감사합니다