
목차
평균으로 돌아가는 회귀현상
한번 돌아(일주하여) 원래로 돌아오는 것. 유전학자 갤톤은 부모와 자식간의 키를 조사하여, 일반적으로 장신인 부모의 아이는 장신이지만, 그 평균신장은 부모만큼 크지 않다는 것을 밝혀냈다. 이것을 평균의 회귀현상이라 하였다. 이런 회귀현상을 유전학 뿐만 아니라 자연현상이나 사회현상에도 적용할 수 있다는 것을 알게 되면서 유전학 뿐만 아니라 여러분야에도 회귀현상을 적용시키게 되었다.
데이터분석 준전문가 3과목 통계분석의 이해 내용 요약
01 회귀분석(Regression analysis)의 개요
회귀분석의 정의
회귀분석(Regression analysis)에서 회귀란 말은 어딘가(?)로 돌아간다는 뜻이다.
왜하는가? 회귀분석의 목적
주어진 (독립)변수로 (종속)변수를 예측하기 위해서 한다.
독립변수들이 종속변수에 미치는 영향을 추정할 수 있는 통계기법이다.
단순회귀: 독립변수 1개 종속변수 1개
다중회귀: 독립변수 2개이상 & 종속변수 1개
회귀분석의 변수
∙원인: 영향을 주는 변수(𝐗) 독립변수다.
다른 변수에 영향을 받지 않고 독립적으로 변화하는 수
또는 설명변수(explanatory variable), 예측변수(predictor variable) y=f(x)에서 X를 독립변수라고 함
∙결과 : 영향을 받는 변수(𝐘) 종속변수다.
독립변수의 영향을 받아 값이 변화하는 수, 분석의 대상이 되는 수이다. 반응변수(reponse variable), 결과변수(outcome variable)
고연봉자(독립변수)가 지출액도 크다(종속변수)고 가설을 세웠다. 💁
고연봉자(X축),지출액(Y축)으로 단순회귀 그래프를 그려볼 수 있겠다. 🧐
기본 회귀분석
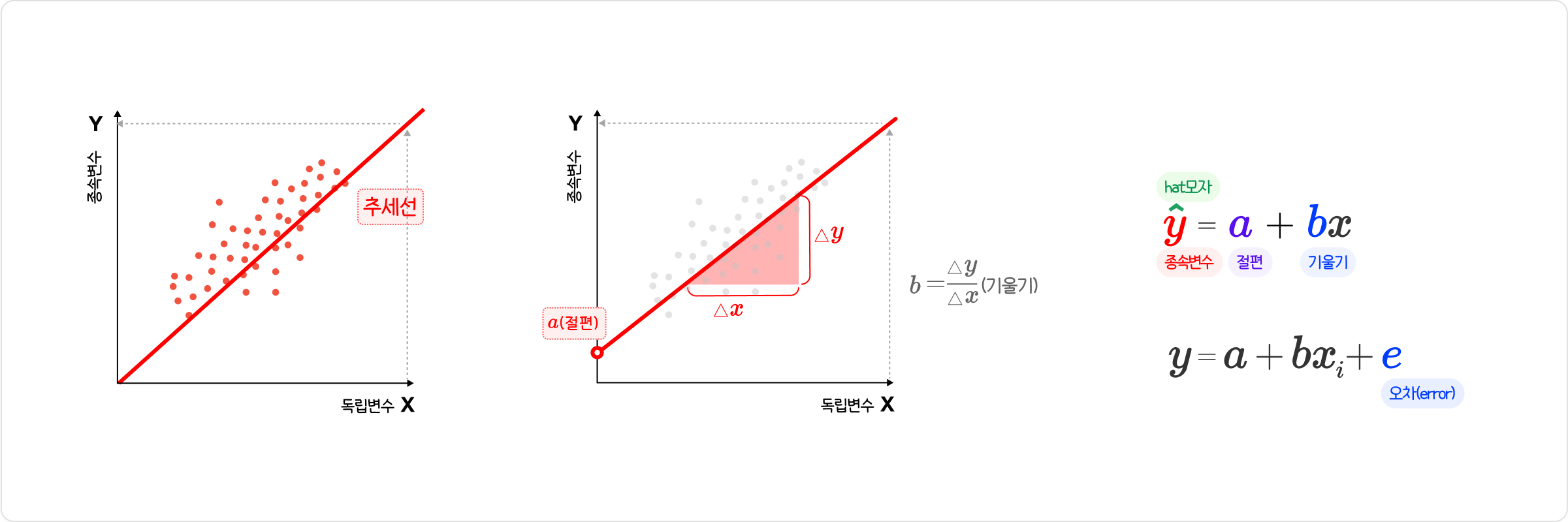
위에 맨쪽 식에서 a와 b의 값을 구해주는 것이 회귀분석이다.
<상세 설명>
a는 절편이라고 부르며 x가 0인 상태에서 y와 만나는 추세선 끝자락이다.
b는 기울기를 뜻한다.
기울기를 구하는 식은 b = X증가량 / y증가량
삼각형 모양의 증가한다는 증가분 기호는 델타 기호를 쓴다.
^ hat은 선들을 가르킨다.
소문자 i는 개별 측정값이다.
e는 오차(error)이다.
추세선 찾기, 오차항 구하기

오차가 가장 작은 추세선이 가장 합리적인 추세선이 될 것이다.
추세선은 그럼 어떻게 구해야 할까?
추세선을 기준선으로 두고 위에 있는 값은 +양의 수가 되고 아래에 있는 값은 -음의 수가 된다.
이 추세선을 회귀분석에서는 회귀직선이라고 부른다.
음수와 양수가 섞인 상태에서 모두 더해버리면 값이 뭉개져 버린다.
그래서 가장 합리적인 추세선을 찾기 위해서는 제곱해서 음수를 양수로 변환한 뒤에 그 수를 합치면 된다.
(제곱해서 음수를 양수로 바꾸는 분산하고 비슷함) 이 합계가 가장 적은 추세선이 가장 오차가 적은 추세선이 된다.
최소제곱법
가장 오차가 적은 회귀직선을 구하는 식을 최소제곱법이라고 한다.
a와 b를 추정하는 방법이며 최소제곱법에 의해 구할 수 있다.
이렇게 구한 추세선은 평균을 반드시 지나는 특징이 있다.
맨 앞에서 서두로 얘기했던 회귀현상을 회귀분석에서도 발견할 수 있다는 점이 재밌다.
[결론]
주어진 데이터의 독립변수로 종속변수를 예측
이를 위해 직선 형태의 추세선을 구함
이 추세선의 식은 y= a+bx a는 절편(Constant) b는 기울기(Slope)
이 추세선을 구하기 위해 사용되는 방법을 최소제곱법이다.
오차의 제곱의 합을 최소로 만드는 방법이다.
최소제곱법으로 구해진 직선이 우리가 원하는 회귀분석의 식이다. 회귀직선을 구하는 것이다.
이 직선은 평균을 지난다.(평균으로의 회귀)
이 방법을 영어로 Ordinary Least Square (OLS)라고 부른다.
Least square가 최소 제곱법이란 의미고 Ordinary가 가장 일반적인, 가장 쉬운 방법을 뜻한다.
회귀분석하는 방법은 다양하지만 모든 회귀분석의 시작은 OLS에서 시작한다.
표준오차구하기 (T-test)
모집단 전체를 분석하는데는 비용이 많이 든다. 그래서 보통은 표본을 구해서 분석을 한다. 당연히 모집단 전체를 분석한게 아니다 보니 표본에서 오차가 생길 수 있다. 이것을 표준 오차라고 부른다.
Q 표준오차란 무엇인가?
표준 오차란 모집단의 평균을 평균의 참값이라고 볼때 표본집단의 평균값이 얼마나 모집단의 평균과 가까운지 아는것이다.
Q 표준오차를 왜 쓰는가?
표준 오차가 적으면 참 값에서 가깝고, 표준 오차가 크면 참 값에서 멀다.
회귀계수는 최소제곱법으로 구해진다. 그렇게 구해진 회귀계수가 우연인지 아닌지 우리는 알 수 없다. 표본을 가지고 평균을 구했으니까..그래서 이 회귀계수가 우연일 확률을 알기 위해 표준오차를 사용한다.
표준오차가 작으면 회귀계수가 우연일 확률이 낮다. 표준오차가 작다는 것은 데이터가 회귀직선에 가까이 퍼져 있단 의미이다. 표준오차가 크다는 것은 데이터가 회귀직선에서 멀리 퍼져 있다는 의미이다. 이 표준 오차를 구하는 방법이 T-test이다.
02 선형회귀분석
(위에서 말한 일반적이 회귀분석은 선형회귀분석을 말한다.)
∙선형성
입력변수와 출력변수의 관계가 선형이다. (선형회귀분석에서 가장 중요한 가정)
∙등분산성
오차의 분산이 입력변수와 무관하게 일정하다.
잔차플롯(산점도)를 활용하여 잔차와 입력변수간에 아무런 관련성이 없게 무작위적으로고루 분포되어야 등분산성 가정을 만족하게 된다.
∙독립성
입력변수와 오차는 관련이 없다. 자기상관(독립성)을 알아보기 위해 Durbin-Waston 통계량을 사용하여 주로 시계열 데이터에서 많이 활용한다.
∙ 비상관성
오차들끼리 상관이 없다.
∙정상성(정규성)
오차의 분포가 정규분포를 따른다. Q-Q plot, Kolmogolov-Smirnov검정, Sharpio-Wilk 검정 등을 활용하여 정규성을 확인한다.
그래프를 활용한 선형회귀분석의 가정 검토
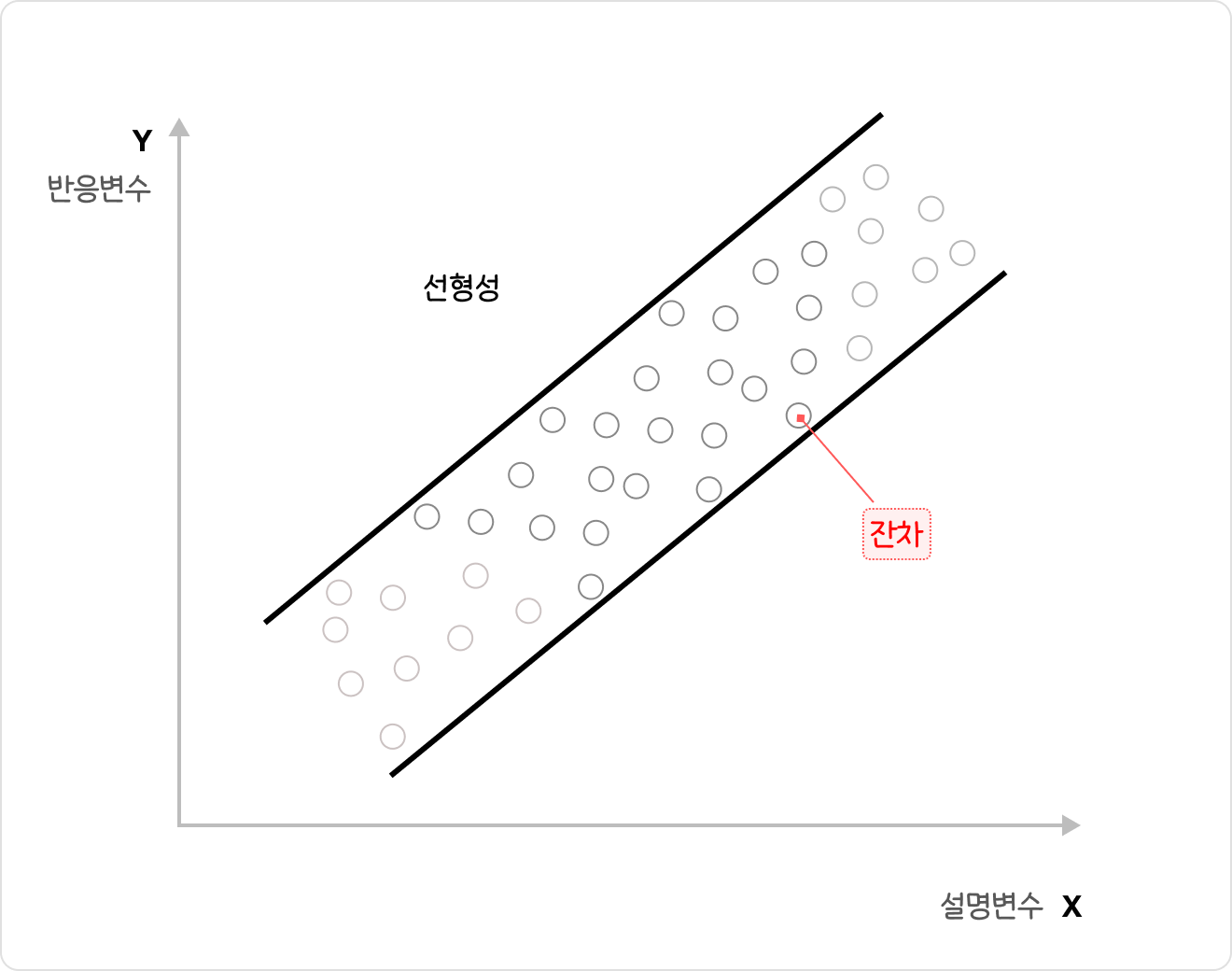
∙선형성
선형회귀모형에서는 아래와 같이 설명변수(x)와 반응변수(y)가 선형적 관계에 있음이 전제 되어야 한다.
∙등분산성
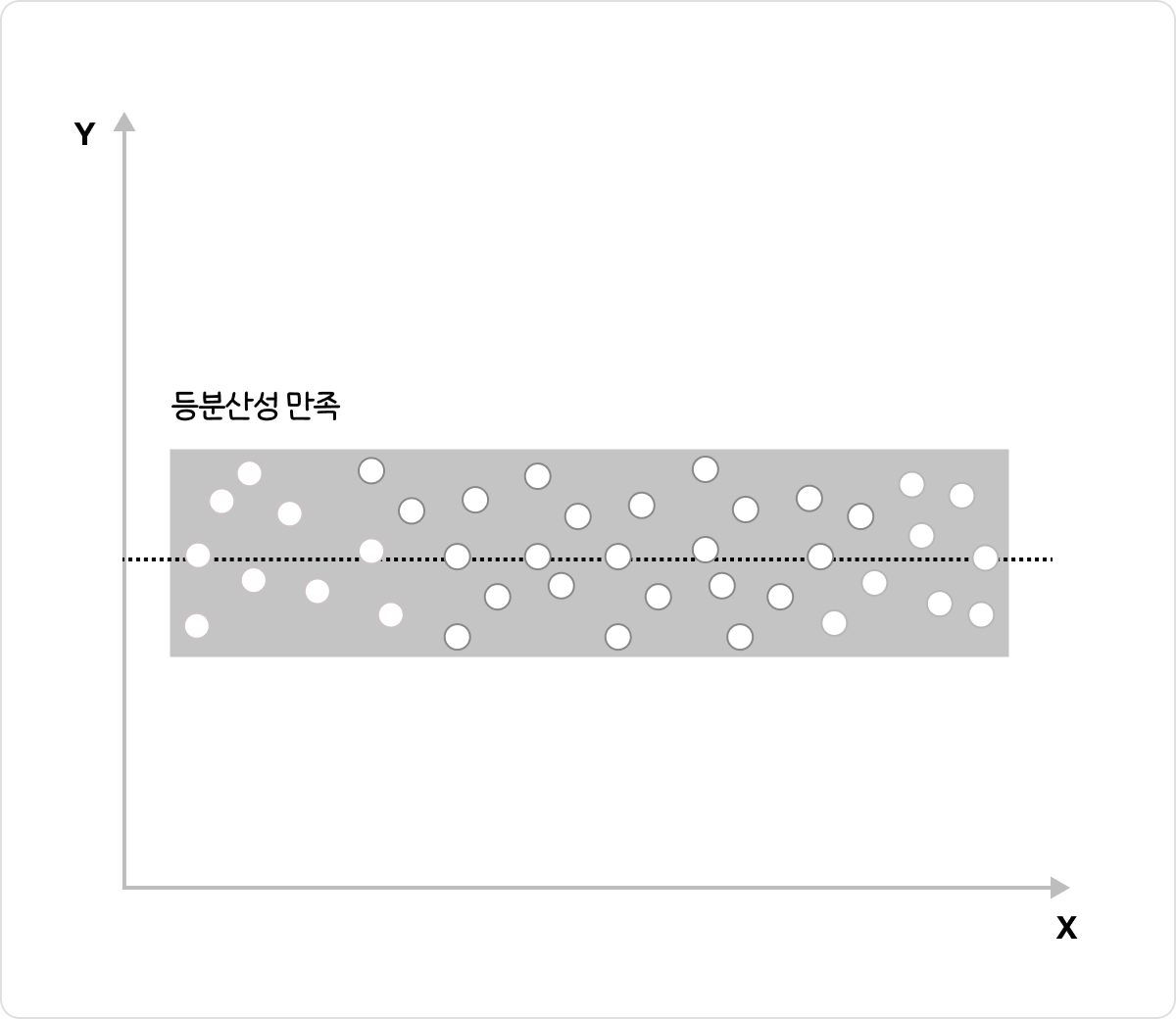
👌 등분산성을 만족하는 경우
설명변수(x)에 대한 잔차의 산점도를 그렸을 때, 아래 그림과 같이 설명변수(x)값에 관계없이 잔차들의 변동성(분산)이 일정한 형태를 보이면 선형회귀분석의 가정중 등분산성을 만족한다고 볼 수 있다.
👎 등분산성을 만족하지 못하는 경우
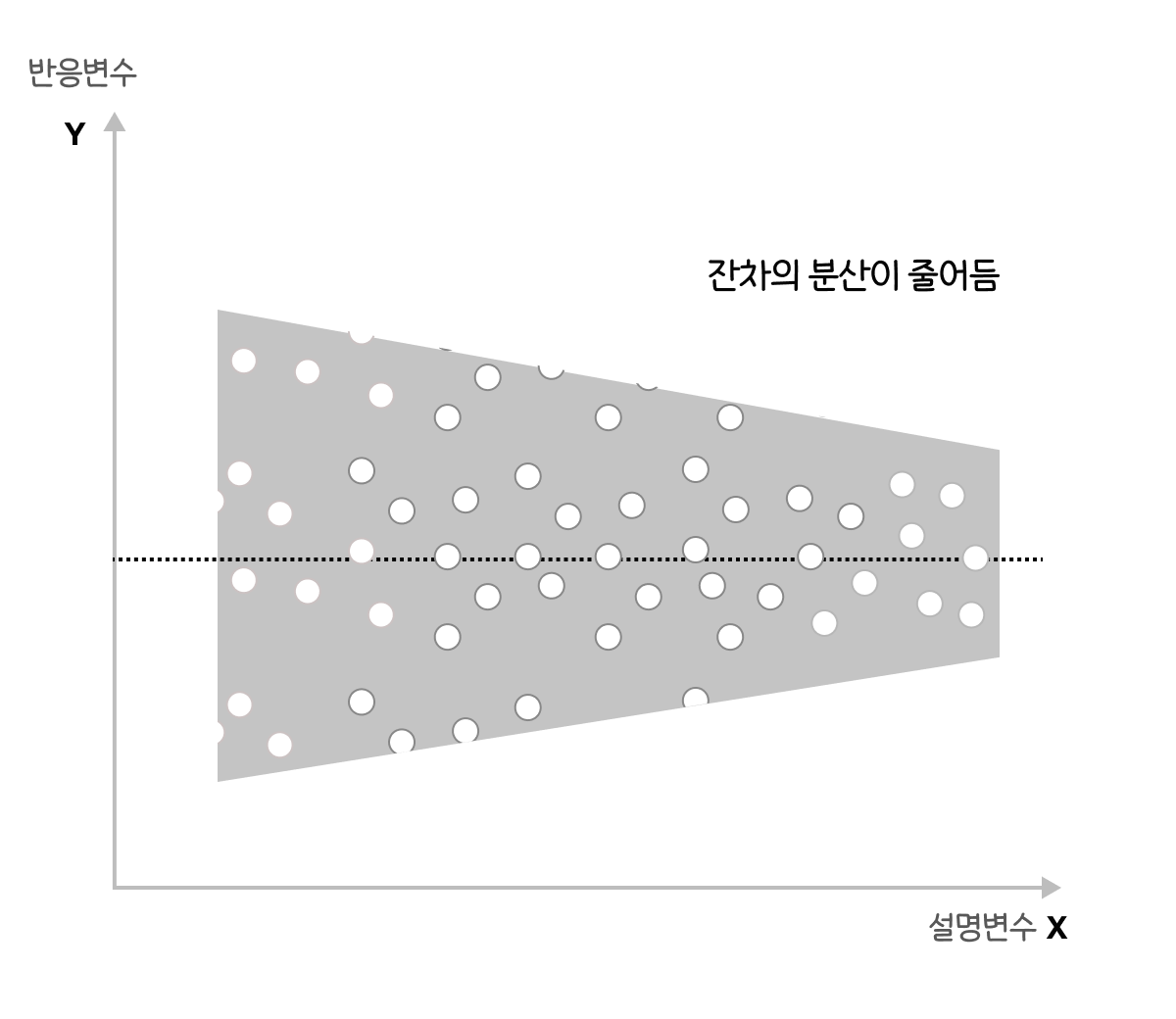 |
설명변수(x)가 커질수록 잔차(오차항)의 분산이 줄어드는 이분산의 형태 |
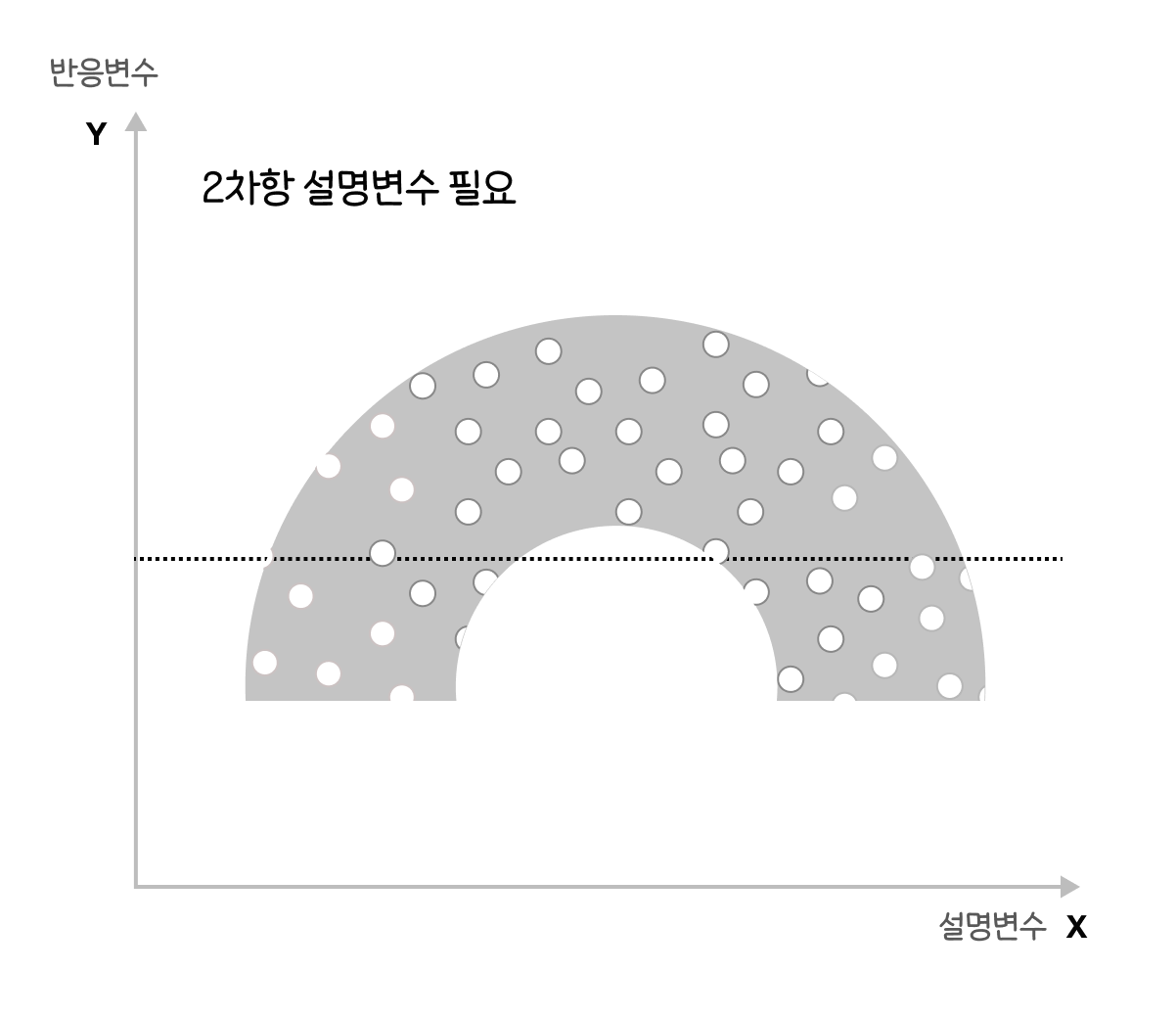 |
2차항 설명변수가 필요할때 |
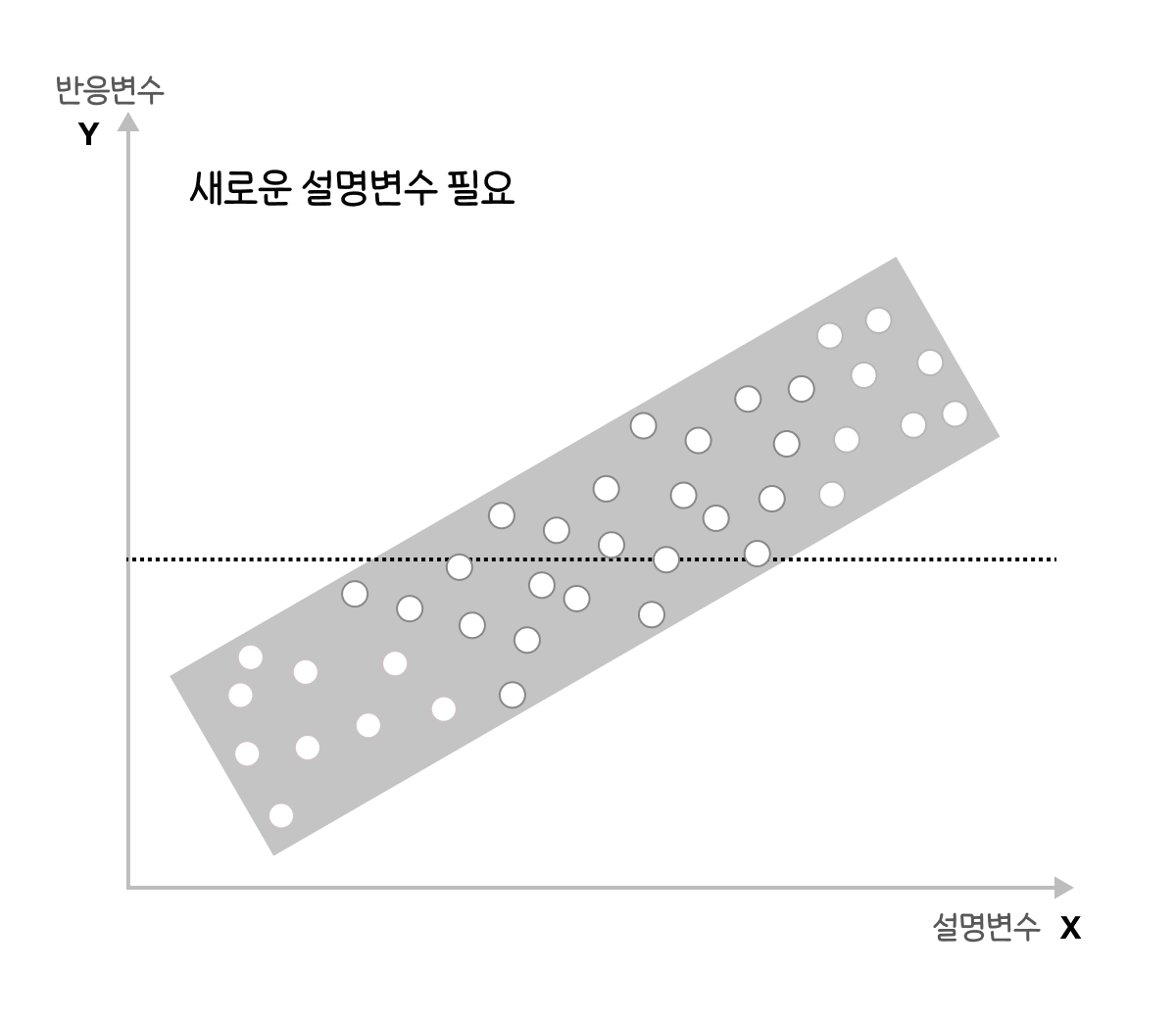 |
새로운 설명변수가 필요 |
∙정규성
Q-Qplot을 출력했을 때, 그림과 같이 잔차가 대각방향의 직선의 형태를 지니고 있으면 잔차는 정규분포를 따른다고 할 수 있다.
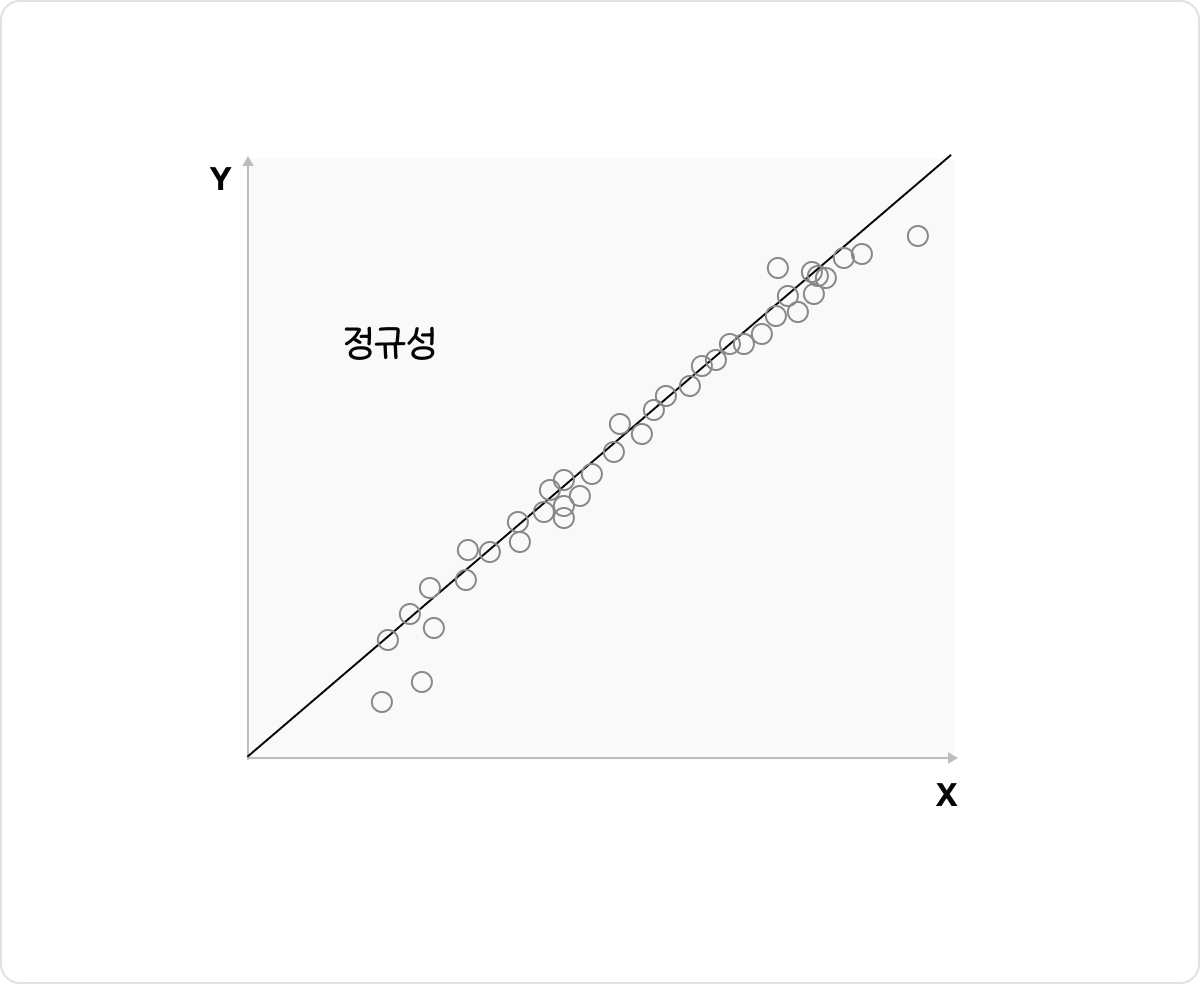
가정에 대한 검증
단순선형회귀분석 : 입력변수와 출력변수간의 선형성을 점검하기 위해 산점도를 확인한다.
다중선형회귀분석 : 선형회귀분석의 가정이 선형성, 등분산성, 독립성, 정상성이 모두 만족하는지 확인해야 한다.
03 단순선형회귀분석
하나의 독립변수가 종속변수에 미치는 영향을 추정할 수 있는 통계기법이다.
𝑦ᵢ = 𝜷₀ + 𝜷₁𝜷𝑥ᵢ +ℇᵢ , 𝑖 =1,2,...𝑛. ɛ𝑖 ~ 𝜨(0.𝝈²)
𝑦: i번째 종속변수 값
𝑥: i번째 독립변수 값
𝜷₀: 선형 회귀식의 절편 (상수항)
𝜷ᵢ: 선형 회귀식의 기울기
𝜀ᵢ : 오차항, 독립적이며 𝑁(0,𝝈²)
회귀분석의 검토사항
1)회귀계수들이 유의미한가?
해당 계수의 t통계량의 p-값이 0.05보다 작으면 해당 회귀계수가 통계적으로 유의하다고 볼 수 있다.
2)모형이 얼마나 설명력을 갖는가?
결정계수(R²)를 확인한다. 결정계수는 0~1값을 가지며, 높은 값을 가질수록 추정된 회귀식의 설명력이 높다.
3)모형이 데이터를 잘 적합하고 있는가?
잔차를 그래프로 그리고 회귀진단을 한다.
회귀계수의 추정 (최소제곱법, 최소자승법)
∙측정값을 기초로 하여 적당한 제곱합을 만들고 그것을 최소로 하는 값을 구하여 측정결과를 처리하는 방법으로 잔차제곱이 가장 작은 선을 구하는 것을 의미한다.
∙추정식
𝑖𝑖𝑑
𝑦ᵢ = 𝜷₀ + 𝜷₁ 𝜷𝑥ᵢ + ℇᵢ , 𝑖 =1,2,...,𝐧. 𝛆𝑖 ~ 𝜨(0.𝝈²)
다. 회귀분석의 검정
1)회귀계수의 검정
∙회귀계수 𝜷₁ 0이면 입력변수 𝑥와 출력변수 𝑦사이에는 아무런 인과관계가 없다.
∙회귀계수 𝜷₁ 이 0이면 적합된 추정식은 아무 의미가 없게 된다. (귀무가설 : 𝜷₁ = 0, 대립가설 𝜷₁ ≠ 0)
04 다중선형회귀분석
다중선형회귀분석(다변량회귀분석)
1)다중회귀식
𝒀 = 𝜷₀ + 𝜷₁𝑿₁ + 𝜷₂𝑿₂ + ...+𝜷𝜅𝑿𝜅 + 𝛆
2) 모형의 통계적 유의성
∙모형의 통계적 유의성을 F통계량으로 확인한다. (R프로그래밍에서 결과값에 F 통계량이 있으면 다중선형회귀분석이다.)
∙유의수준 5% 하에서 F통계량의 p-값이 0.05보다 작으면 회귀식은 통계적으로 유의하다고 볼 수 있다.
∙F통계량이 크면 p-value가 0.05보다 작아지고 이렇게 되면 귀무가설을 기각한다. 즉 모형이 유의하다고 결론지을 수 있다.
3) 회계 계수의 유의성
∙회계게수의 유의성은 다변량 회귀분석의 회귀계수 유의성 검토와 같이 t통계량을 통해 확인한다.
∙모든 회귀계수의 유의성이 통계적으로 검증되어야 선택된 변수들의 조합으로 모형을 활용할 수 있다.
4)모형의 설명력결정계수 (R²)나 수정된 결정계수(R2a)를 확인한다.
5) 모형의 적합성
모형이 데이터를 잘 적합하고 있는지 잔차와 종속변수의 산점도로 확인한다.
6) 데이터가 전제하는 가정을 만족시키는가?
선형성, 독립성, 등분산성, 비상관성, 정상성
7)다중공선성(multicollinearity)
다중회귀분석에서 설명변수들 사이에 선형관계가 존재하면 회귀계수의 정확한 추정이 곤란하다.
다중공선성 검사 방법:
분산팽창요인(VIF) : 4보다 크면 다중공선성이 존재한다고 볼 수 있고, 10보다 크면 심각한 문제가 있는 것으로 해석할 수 있다. - 상태지수 : 10 이상이면 문제가 있다고 보고, 30보다 크면 문제가 있다고 해석할 수 있다. 다중선형회귀분석에서 다중공선성의 문제가 발생하면, 문제가 있는 변수를 제거하거나 주성분회귀, 능형회귀 모형을 적용하여 문제를 해결한다.
05 회귀분석의 종류
| 단순회귀 | 𝒀=𝜷₀ + 𝜷₁𝑿 + 𝛆 | 독립변수가 1개이며 종속변수와의 관계가 직선 |
| 다중회귀 | 𝒀=𝜷₀ + 𝜷₁𝑿₁ | 독립변수가 k개이며 종속변수와의 관계가 선형(1차함수) |
| 로지스틱회귀 | 𝒀=𝜷₀ + 𝜷₁𝑿₁ | 종속변수가 범주형(2진변수)인 경우에 적용되며, 단순 로지스틱 회귀 및 다중, 다항 로지스틱 회귀로 확장할 수 있음 |
| 다항회귀 | 𝒀=𝜷₀ + 𝜷₁𝑿₁ | 독립변수와 종속변수와의 관계가 1차함수 이상인 관계(단 k=1이면 2차 함수 이상) |
| 곡선회귀 | 2차곡선 𝒀=𝜷₀ + 𝜷₁𝑿 + 𝜷₂𝑿² + 𝛆 3차곡선 𝒀=𝜷₀ + 𝜷₁𝑿 + 𝜷₂𝑿² + 𝜷₃𝑿³ + 𝛆 |
독립변수가 1개이며 종속변수와의 관계가 곡선 |
| 비선형회귀 | 𝒀=𝜶𝑒¯ᵝˣ + 𝛆 | 회귀식의 모양이 미지의 모수들이며 선형관계로 이뤄져 있지 않은 모형 |
06 회귀분석 R프로그램에서 사용하는 방법
lm(Y~X)를 함수를 사용하면 쉽게 구할 수 있다.
1) 회귀식
attach(df)
lm(overall~rides)
call
lm(fomula=overall~rides)
Coefficients:
(Intercept) rides
-94.962 1.703𝜷₀ =-94.962
𝜷₁ = 1.703
overall(Y) =-94.962(𝜷₀ ) + 1.703(𝜷₁)* rides(X) 라는 회귀식을 만들 수 있고
놀이기구에 대한 만족도(rides)가 1이 증가할때 전체 만족도 (overall)이 1.703이 증가한다고 볼 수 있다.
2) 산점도 그려보기
m01 <- lm(overall~rides)
plot(overall~rides, xlab="satisfaction with Rides", ylab="Overall satisfaction")
abline(m01,col='blue')
3) summary()함수를 통해 F통계량 , p-value, 잔차에 대한 정보 ,R제곱 등 확인해보기
summary(m01)
'데이터분석준전문가(ADsP) > 3과목' 카테고리의 다른 글
| [정형데이터 마이닝] 군집분석 (0) | 2021.08.25 |
|---|---|
| [정형데이터 마이닝 ] 데이터 마이닝 (0) | 2021.08.21 |
| [통계분석] 주성분분석 (0) | 2021.08.14 |
| [통계분석] 다차원척도법 (0) | 2021.08.14 |
| [정형데이터마이닝] 앙상블 분석 (0) | 2021.08.14 |
| [통계분석] 시계열 분석 (3) | 2021.08.13 |
| [통계분석] 통계기초 - 수학기호&통계기호 (1) | 2021.08.12 |
| [통계분석] 통계분석의 이해 (0) | 2021.08.08 |



